
新浪科技讯 2月5日下昼音问,近日,面壁智能聚拢首创东说念主兼首席科学家刘知远在谈及DeepSeek近期激发的飞腾时指出,“DeepSeek 最近发布R1模子的紧迫价值在于它卤莽齐全复现OpenAI o1的深度推理身手,而况他通过开源的现象发布了相对贯注的先容,为行业作出了紧迫孝顺。”
刘知远指出,“因为OpenAI o1本人并莫得提供对于其已毕细节的任何信息,它相当于引爆了一个原枪弹,但莫得告诉各人秘方,而DeepSeek可能是全球首个能通过纯正的强化学习本领复现OpenAI o1身手的团队,而况还把这种身手开源了。”
刘知远追忆指出,DeepSeek R1的总共这个词检会进程有两个格外紧迫的亮点或价值:一是通过轨则启动的要津已毕了大限度强化学习;二是通过深度推理 SFT 数据与通用 SFT 数据的羼杂微调,已毕了推理身手的跨任务泛化;这使得 DeepSeek R1 卤莽见效复现OpenAI o1 的推理水平。
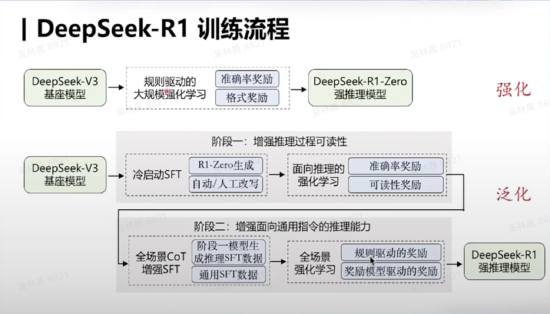
领先,DeepSeek R1创造性地基于DeepSeek V3基座模子,通过大限度强化学习本领,得到了一个纯正通过强化学习增强的强推理模子,即DeepSeek-R1-Zero,这具有格外紧迫的价值,因为在历史上险些莫得团队卤莽见效地坚硬化学习本领很好地欺诈于大限度模子上,并已毕大限度检会。DeepSeek卤莽已毕大限度强化学习的一个紧迫本领特质是其遴选了基于轨则(rule-based)的要津,确保强化学习不错限度化,并已毕面向强化学习的膨胀(Scaling),这是它的第一个孝顺。
其次,DeepSeek R1 的第二个紧迫孝顺在于其强化学习本领不仅局限于数学、算法代码等容易提供奖励信号的规模,还能创造性地坚硬化学习带来的强推理身手泛化到其他规模。这亦然用户在本色使用DeepSeek R1进行写稿等任务时,卤莽感受到其宏大的深度念念考身手的原因。
“这种泛化身手的已毕分为两个阶段:领先,基于DeepSeek V3基座模子,通过增强推理过程的可读性,生成了带有深度推理身手的SFT(Supervised Fine-Tuning)数据,这种数据衔尾了深度推理身手和传统通用SFT数据,用于微调大模子;随后,进一步通过强化学习检会,得到了具有宏大泛化身手的强推理模子,即 DeepSeek R1。”刘知远示意。
在他看来,DeepSeek R1卤莽得到如斯全球性的见效呢,与OpenAI在发布o1之后剿袭不开源,同期将o1深度念念考的过程袒护起来,而况遴选了格外高的收费现象相干。“这使得o1无法在全球范围内让尽可能多的东说念主普惠地感受到深度念念考所带来的轰动,而DeepSeek R1则像2023岁首 OpenAI的ChatGPT雷同,让总共东说念主着实感受到了这种轰动,这是 DeepSeek R1 出圈的格外紧迫的原因。”(文猛)
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
包袱剪辑:王若云 无人不知无人不晓

官网:www.help178.com

邮箱:950490cb@outlook.com

联系:40708926497

地址:新闻中心电子工业园1114号